
Methodology for incident response on generative AI workloads
The AWS Customer Incident Response Team (CIRT) has developed a methodology that you can use to investigate security incidents involving generative AI-based applications. To respond to security events related to a generative AI workload, you should still follow the guidance and principles outlined in the AWS Security Incident Response Guide. However, generative AI workloads require that you also consider some additional elements, which we detail in this blog post.
We start by describing the common components of a generative AI workload and discuss how you can prepare for an event before it happens. We then introduce the Methodology for incident response on generative AI workloads, which consists of seven elements that you should consider when triaging and responding to a security event on a generative AI workload. Lastly, we share an example incident to help you explore the methodology in an applied scenario.
Components of a generative AI workload
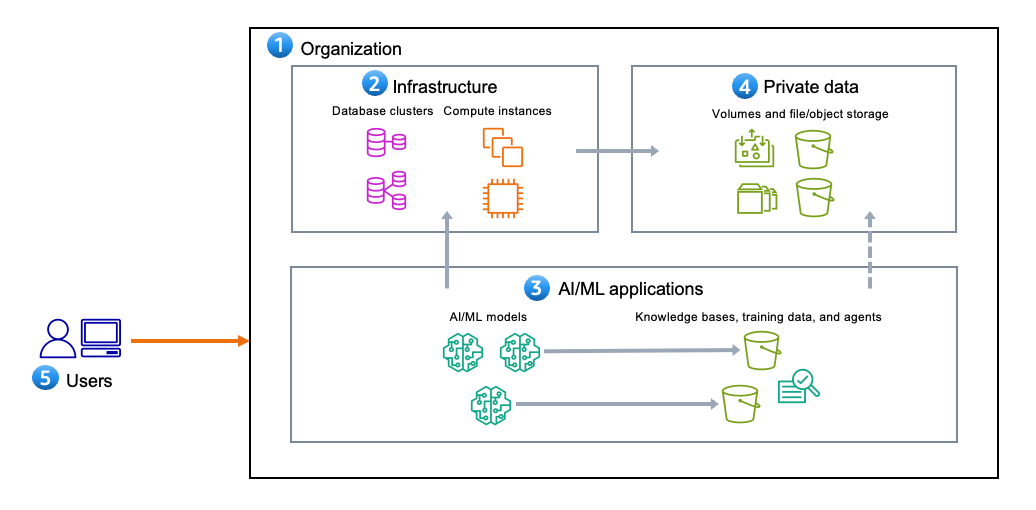
As shown in Figure 1, generative AI applications include the following five components:
- An organization that owns or is responsible for infrastructure, generative AI applications, and the organization’s private data.
- Infrastructure within an organization that isn’t specifically related to the generative AI application itself. This can include databases, backend servers, and websites.
- Generative AI applications, which include the following:
- Foundation models – AI models with a large number of parameters and trained on a massive amount of diverse data.
- Custom models – models that are fine-tuned or trained on an organization’s specific data and use cases, tailored to their unique requirements.
- Guardrails – mechanisms or constraints to help make sure that the generative AI application operates within desired boundaries. Examples include content filtering, safety constraints, or ethical guidelines.
- Agents – workflows that enable generative AI applications to perform multistep tasks across company systems and data sources.
- Knowledge bases – repositories of domain-specific knowledge, rules, or data that the generative AI application can access and use.
- Training data – data used to train, fine-tune, or augment the generative AI application’s models, including data for techniques such as retrieval augmented generation (RAG).
Note: Training data is distinct from an organization’s private data. A generative AI application might not have direct access to private data, although this is configured in some environments.
- Plugins – additional software components or extensions that you can integrate with the generative AI application to provide specialized functionalities or access to external services or data sources.
- Private data refers to the customer’s privately stored, confidential data that the generative AI resources or applications aren’t intended to interact with during normal operation.
- Users are the identities that can interact with or access the generative AI application. They can be human or non-human (such as machines).

Figure 1: Common components of an AI/ML workload
Prepare for incident response on generative AI workloads
You should prepare for a security event across three domains: people, process, and technology. For a summary of how to prepare, see the preparation items from the Security Incident Response Guide. In addition, your preparation for a security event that’s related to a generative AI workload should include the following:
- People: Train incident response and security operations staff on generative AI – You should make sure that your staff is familiar with generative AI concepts and with the AI/ML services in use at your organization. AWS Skill Builder provides both free and paid courses on both of these subjects.
- Process: Develop new playbooks – You should develop new playbooks for security events that are related to a generative AI workload. To learn more about how to develop these, see the following sample playbooks:
- Responding to Amazon Bedrock Security Events
- Responding to SageMaker Security Events
- Responding to Amazon Q Security Events.
You can use these playbooks as a starting point and modify them to best fit your organization and usage of these services.
- Technology: Log generative AI application prompts and invocations – In addition to foundational logs, such as those available in AWS CloudTrail, you should consider logging Amazon Bedrock model invocation logs so that you can analyze the prompts coming into your application and the outputs. To learn more, see Amazon Bedrock model invocation logging. CloudTrail data event logging is also available for Amazon Bedrock, Amazon Q, and Amazon SageMaker. For general guidance, see Logging strategies for security incident response.
Important: Logs can contain sensitive information. To help protect this information, you should set up least privilege access to these logs, like you do for your other security logs. You can also protect sensitive log data with data masking. In Amazon CloudWatch, you can mask data natively through log group data protection policies.
Methodology for incident response on generative AI workloads
After you complete the preparation items, you can use the Methodology for incident response on generative AI workloads for active response, to help you rapidly triage an active security event involving a generative AI application.
The methodology has seven elements, which we detail in this section. Each element describes a method by which the components can interact with another component or a method by which a component can be modified. Consideration of these elements will help guide your actions during the Operations phase of a security incident, which includes detection, analysis, containment, eradication, and recovery phases.
- Access – Determine the designed or intended access patterns for the organization that hosts the components of the generative AI application, and look for deviations or anomalies from those patterns. Consider whether the application is accessible externally or internally because that will impact your analysis. To help you identify anomalous and potential unauthorized access to your AWS environment, you can use Amazon GuardDuty. If your application is accessible externally, the threat actor might not be able to access your AWS environment directly and thus GuardDuty won’t detect it. The way that you’ve set up authentication to your application will drive how you detect and analyze unauthorized access. If evidence of unauthorized access to your AWS account or associated infrastructure exists, determine the scope of the unauthorized access, such as the associated privileges and timeline. If the unauthorized access involves service credentials—for example, Amazon Elastic Compute Cloud (Amazon EC2) instance credentials—review the service for vulnerabilities.
- Infrastructure changes – Review the supporting infrastructure, such as servers, databases, serverless computing instances, and internal or external websites, to determine if it was accessed or changed. To investigate infrastructure changes, you can analyze CloudTrail logs for modifications of in-scope resources, or analyze other operating system logs or database access logs.
- AI changes – Investigate whether users have accessed components of the generative AI application and whether they made changes to those components. Look for signs of unauthorized activities, such as the creation or deletion of custom models, modification of model availability, tampering or deletion of generative AI logging capabilities, tampering with the application code, and removal or modification of generative AI guardrails.
- Data store changes – Determine the designed or intended data access patterns, whether users accessed the data stores of your generative AI application, and whether they made changes to these data stores. You should also look for the addition or modification of agents to a generative AI application.
- Invocation – Analyze invocations of generative AI models, including the strings and file inputs, for threats, such as prompt injection or malware. You can use the OWASP Top 10 for LLM as a starting point to understand invocation related threats, and you can use invocation logs to analyze prompts for suspicious patterns, keywords, or structures that might indicate a prompt injection attempt. The logs also capture the model’s outputs and responses, enabling behavioral analysis to help identify uncharacteristic or unsafe model behavior indicative of a prompt injection. You can use the timestamps in the logs for temporal analysis to help detect coordinated prompt injection attempts over time and collect information about the user or system that initiated the model invocation, helping to identify the source of potential exploits.
- Private data – Determine whether the in-scope generative AI application was designed to have access to private or confidential data. Then look for unauthorized access to, or tampering with, that data.
- Agency – Agency refers to the ability of applications to make changes to an organization’s resources or take actions on a user’s behalf. For example, a generative AI application might be configured to generate content that is then used to send an email, invoking another resource or function to do so. You should determine whether the generative AI application has the ability to invoke other functions. Then, investigate whether unauthorized changes were made or if the generative AI application invoked unauthorized functions.
The following table lists some questions to help you address the seven elements of the methodology. Use your answers to guide your response.
| Topic | Questions to address |
| Access | Do you still have access to your computing environment? Is there continued evidence of unauthorized access to your organization? |
| Infrastructure changes | Were supporting infrastructure resources accessed or changed? |
| AI changes | Were your AI models, code, or resources accessed or changed? |
| Data store changes | Were your data stores, knowledge bases, agents, plugins, or training data accessed or tampered with? |
| Invocation | What data, strings, or files were sent as input to the model? What prompts were sent? What responses were produced? |
| Private data | What private or confidential data do generative AI resources have access to? Was private data changed or tampered with? |
| Agency | Can the generative AI application resources be used to start computing services in an organization, or do the generative AI resources have the authority to make changes? Were unauthorized changes made? |
Example incident
To see how to use the methodology for investigation and response, let’s walk through an example security event where an unauthorized user compromises a generative AI application that’s hosted on AWS by using credentials that were exposed on a public code repository. Our goal is to determine what resources were accessed, modified, created, or deleted.
To investigate generative AI security events on AWS, these are the main log sources that you should review:
- CloudTrail
- CloudWatch
- VPC Flow Logs
- Amazon Simple Storage Service (Amazon S3) data events (for evidence of access to an organization’s S3 buckets)
- Amazon Bedrock model invocation logs (if your application uses this service)
Access
Analysis of access for a generative AI application is similar to that for a standard three-tier web application. To begin, determine whether an organization has access to their AWS account. If the password for the AWS account root user was lost or changed, reset the password. Then, we strongly recommended that you immediately enable a multi-factor authentication (MFA) device for the root user—this should block a threat actor from accessing the root user.
Next, determine whether unauthorized access to the account persists. To help identify mutative actions logged by AWS Identity and Access Management (IAM) and AWS Security Token Service (Amazon STS), see the Analysis section of the Compromised IAM Credentials playbook on GitHub. Lastly, make sure that access keys aren’t stored in public repositories or in your application code; for alternatives, see Alternatives to long-term access keys.
Infrastructure changes
To analyze the infrastructure changes of an application, you should consider both the control plane and data plane. In our example, imagine that Amazon API Gateway was used for authentication to the downstream components of the generative AI application and that other ancillary resources were interacting with your application. Although you could review control plane changes to these resources in CloudTrail, you would need additional logging to be turned on to review changes made on the operating system of the resource. The following are some common names for control plane events that you could find in CloudTrail for this element:
ec2:RunInstancesec2:StartInstancesec2:TerminateInstancesecs:CreateClustercloudformation:CreateStackrds:DeleteDBInstancerds:ModifyDBClusterSnapshotAttribute
AI changes
Unauthorized changes can include, but are not limited to, system prompts, application code, guardrails, and model availability. Internal user access to the generative AI resources that AWS hosts are logged in CloudTrail and appear with one of the following event sources:
bedrock.amazonaws.comsagemaker.amazonaws.comqbusiness.amazonaws.comq.amazonaws.com
The following are a couple examples of the event names in CloudTrail that would represent generative AI resource log tampering in our example scenario:
bedrock:PutModelInvocationLoggingConfigurationbedrock:DeleteModelInvocationLoggingConfiguration
The following are some common event names in CloudTrail that would represent access to the AI/ML model service configuration:
bedrock:GetFoundationModelAvailabilitybedrock:ListProvisionedModelThroughputsbedrock:ListCustomModelsbedrock:ListFoundationModelsbedrock:ListProvisionedModelThroughputbedrock:GetGuardrailbedrock:DeleteGuardrail
In our example scenario, the unauthorized user has gained access to the AWS account. Now imagine that the compromised user has a policy attached that grants them full access to all resources. With this access, the unauthorized user can enumerate each component of Amazon Bedrock and identify the knowledge base and guardrails that are part of the application.
The unauthorized user then requests model access to other foundation models (FMs) within Amazon Bedrock and removes existing guardrails. The access to other foundation models could indicate that the unauthorized user intends to use the generative AI application for their own purposes, and the removal of guardrails minimizes filtering or output checks by the model. AWS recommends that you implement fine-grained access controls by using IAM policies and resource-based policies to restrict access to only the necessary Amazon Bedrock resources, AWS Lambda functions, and other components that the application requires. Also, you should enforce the use of MFA for IAM users, roles, and service accounts with access to critical components such as Amazon Bedrock and other components of your generative AI application.
Data store changes
Typically, you use and access a data store and knowledge base through model invocation, and for Amazon Bedrock, you include the API call bedrock:InvokeModel.
However, if an unauthorized user gains access to the environment, they can create, change, or delete the data sources and knowledge bases that the generative AI applications integrate with. This could cause data or model exfiltration or destruction, as well as data poisoning, and could create a denial-of-service condition for the model. The following are some common event names in CloudTrail that would represent changes to AI/ML data sources in our example scenario:
bedrock:CreateDataSourcebedrock:GetKnowledgeBasebedrock:DeleteKnowledgeBasebedrock:CreateAgentbedrock:DeleteAgentbedrock:InvokeAgentbedrock:Retrievebedrock:RetrieveAndGenerate
For the full list of possible actions, see the Amazon Bedrock API Reference.
In this scenario, we have established that the unauthorized user has full access to the generative AI application and that some enumeration took place. The unauthorized user then identified the S3 bucket that was the knowledge base for the generative AI application and uploaded inaccurate data, which corrupted the LLM. For examples of this vulnerability, see the section LLM03 Training Data Poisoning in the OWASP TOP 10 for LLM Applications.
Invocation
Amazon Bedrock uses specific APIs to register model invocation. When a model in Amazon Bedrock is invoked, CloudTrail logs it. However, to determine the prompts that were sent to the generative AI model and the output response that was received from it, you must have configured model invocation logging.
These logs are crucial because they can reveal important information, such as whether a threat actor tried to get the model to divulge information from your data stores or release data that the model was trained or fine-tuned on. For example, the logs could reveal if a threat actor attempted to prompt the model with carefully crafted inputs that were designed to extract sensitive data, bypass security controls, or generate content that violates your policies. Using the logs, you might also learn whether the model was used to generate misinformation, spam, or other malicious outputs that could be used in a security event.
Note: For services such as Amazon Bedrock, invocation logging is disabled by default. We recommend that you enable data events and model invocation logging for generative AI services, where available. However, your organization might not want to capture and store invocation logs for privacy and legal reasons. One common concern is users entering sensitive data as input, which widens the scope of assets to protect. This is a business decision that should be taken into consideration.
In our example scenario, imagine that model invocation wasn’t enabled, so the incident responder couldn’t collect invocation logs to see the model input or output data for unauthorized invocations. The incident responder wouldn’t be able to determine the prompts and subsequent responses from the LLM. Without this logging enabled, they also couldn’t see the full request data, response data, and metadata associated with invocation calls.
Event names in model invocation logs that would represent model invocation logging in Amazon Bedrock include:
bedrock:InvokeModelbedrock:InvokeModelWithResponseStreambedrock:Conversebedrock:ConverseStream
The following is a sample log entry for Amazon Bedrock model invocation logging:

Figure 2: sample model invocation log including prompt and response
Private data
From an architectural standpoint, generative AI applications shouldn’t have direct access to an organization’s private data. You should classify data used to train a generative AI application or for RAG use as data store data and segregate it from private data, unless the generative AI application uses the private data (for example, in the case where a generative AI application is tasked to answer questions about medical records for a patient). One way to help make sure that an organization’s private data is segregated from generative AI applications is to use a separate account and to authenticate and authorize access as necessary to adhere to the principle of least privilege.
Agency
Excessive agency for an LLM refers to an AI system that has too much autonomy or decision-making power, leading to unintended and potentially harmful consequences. This can happen when an LLM is deployed with insufficient oversight, constraints, or alignment with human values, resulting in the model making choices that diverge from what most humans would consider beneficial or ethical.
In our example scenario, the generative AI application has excessive permissions to services that aren’t required by the application. Imagine that the application code was running with an execution role with full access to Amazon Simple Email Service (Amazon SES). This could allow for the unauthorized user to send spam emails on the users’ behalf in response to a prompt. You could help prevent this by limiting permission and functionality of the generative AI application plugins and agents. For more information, see OWASP Top 10 for LLM, evidence of LLM08 Excessive Agency.
During an investigation, while analyzing the logs, both the sourceIPAddress and the userAgent fields will be associated with the generative AI application (for example, sagemaker.amazonaws.com, bedrock.amazonaws.com, or q.amazonaws.com). Some examples of services that might commonly be called or invoked by other services are Lambda, Amazon SNS, and Amazon SES.
Conclusion
To respond to security events related to a generative AI workload, you should still follow the guidance and principles outlined in the AWS Security Incident Response Guide. However, these workloads also require that you consider some additional elements.
You can use the methodology that we introduced in this post to help you address these new elements. You can reference this methodology when investigating unauthorized access to infrastructure where the use of generative AI applications is either a target of unauthorized use, the mechanism for unauthorized use, or both. The methodology equips you with a structured approach to prepare for and respond to security incidents involving generative AI workloads, helping you maintain the security and integrity of these critical applications.
For more information about best practices for designing your generative AI application, see Generative AI for the AWS Security Reference Architecture. For information about tactical mitigations for a common generative AI application, see the Blueprint for secure design and anti-pattern mitigation.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Security, Identity, & Compliance re:Post or contact AWS Support.
You must be logged in to post a comment.