
Face mask recognition with ML/AI on Cisco industrial hardware
Picture you’ve been asked to generate an architecture that may apply analytics on extremely voluminous information such as video clip streams generated from digital cameras. Provided the sensitivity and level of the data, you would like to send it off-premises for analysis don’t. Also, the anticipated cost of centralizing the info may invalidate your organization value assessment to use case. You could apply device learning (ML) or synthetic cleverness (AI) at the edge-but only when you may make it use the available compute assets.
This is actually the exact challenge I tackled by using my colleague recently, Michael Wielpuetz.
It’s not necessarily easy as well as possible to improve or scale the offered compute resources in an average edge situation. A ML- or AI-enabled software stack includes libraries, frameworks, and educated analytical models. With regards to the available sources at the network advantage, the frameworks and the versions are generally large in proportions. Additionally, such setups require several CPU- often, or GPU-enabled conditions during operation even.
To provide foods for thought, to incubate brand new ideas, also to proof probability, Michael Wielpuetz and I were only available in our free period to reduce the resource dependence on an exemplary set up. We considered a use situation that relates to an ongoing public challenge: detect individual faces on a movie stream and whether those faces are usually covered with a security mask.
We decided to develop a base Docker picture which allows us to web host two stacked neural systems: The initial neural system to detect all faces in the video stream, and the next neural network to detect masks on the true faces found. To reduce the container, in addition to to have it obtainable across ARM64 and x86_64 architectures, we compiled, cross-compiled, and minimized the footprint of most parts from gigabyte to megabyte dimension. To allow using among the smallest achievable AI frameworks, we changed, quantized, and stripped the qualified models. We made a decision to invest the excess hard work for optimizing the frameworks and libraries since when we started there is no ready-to-use installable bundle available for the newest versions of the elements.
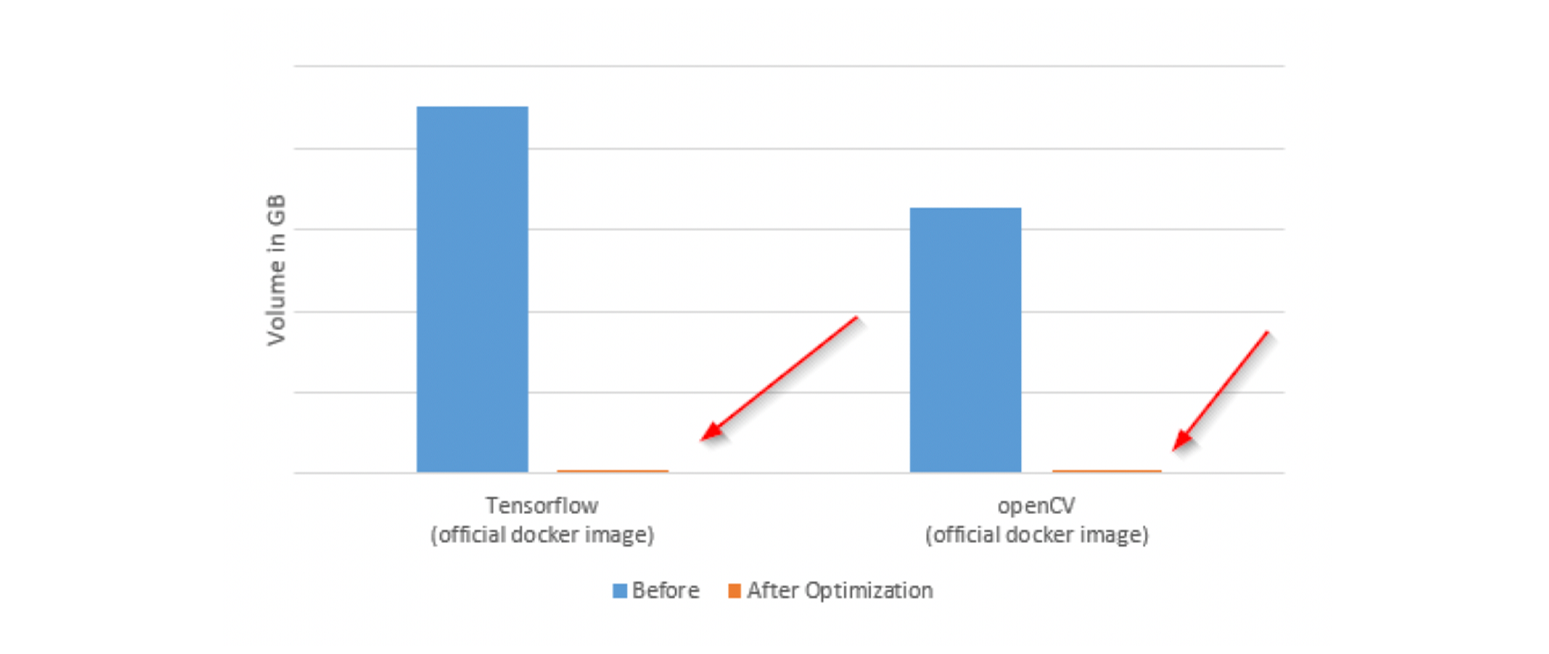
See how the typical Docker images evaluate to your base image:

The ultimate size of our picture on ARM64 is 184MB, and there’s prospect of further optimization still.
Both neural networks are embedded into a credit card applicatoin that allows powerful configuration, such as for example configuring the video stream to be utilized, defining the resolution and the sampling rate, and much more. These configurations have a significant impact on the info and throughput availability latency of the setup.
On the operational techniques we tested, the throughput was around five fps at an answer of 720p with just a area of the available assets distributed around the Docker container to permit for several containers to be hosted simultaneously. The perfect setting and necessary throughput depend on the utilization case requirements. Most of the use cases we considered are great with one body per second as well as less perfectly.
The inner architecture of the Docker container is really as follows:

Because the base Docker image works together with configurable video streams, it’s an easy task to think about additional use cases. It will become an exercise of changing or retraining the design to cover additional scenarios predicated on video streams make it possible for use situations like detecting area occupation, people counting, risk detection, object recognition and many more.
Is an exemplory case of the setup doing his thing here. The video will highlight:
-
- in the initial segment, the dynamically anonymized faces are usually detected
- in the next segment, a visual representation of the analytical outcome, like the face location, the facial functions, and also the probability a mask
has been worn by the individual
- in the 3rd segment, the initial input video stream with a visualization of the detections
- in the fourth segment, the output of the setup
The fourth segment is what this setup provides to external consumers exactly. To maintain privacy, the setup won’t send image or video information outbound.
There’s room for optimizing the accuracy of the analytical results still. For this first set up, we intentionally established our concentrate on the proof possibility and reference allocation reduction of executing ML and AI at the advantage, than developing a ready-to-use product rather.
We plan on developing a couple of other examples predicated on movie, then we’ll switch our focus to device telemetry and how exactly we can use this process on high dimensional information. Our plan would be to continue to release various Docker images for various use cases to greatly help others getting started off with ML and AI at the advantage.
You can find the Docker image here.
The post Face mask detection with ML/AI on Cisco industrial hardware appeared very first on Cisco Blogs.